The value inversion: Why AI has changed everything – and nothing – about content strategy's value
Two decades of content debt has been quietly accumulating. AI is the collections notice.

For twenty-five years, we built digital products the same way.
Engineers built the infrastructure.
↓
Designers crafted the interface.
↓
Content got plugged in at the end.
This worked because interfaces were most of the value. A well-designed, intuitive website could succeed with mediocre content. Users forgave unclear copy if the experience was smooth. Content was important, but it was the 5% you sorted out once the ‘real work’ was done.
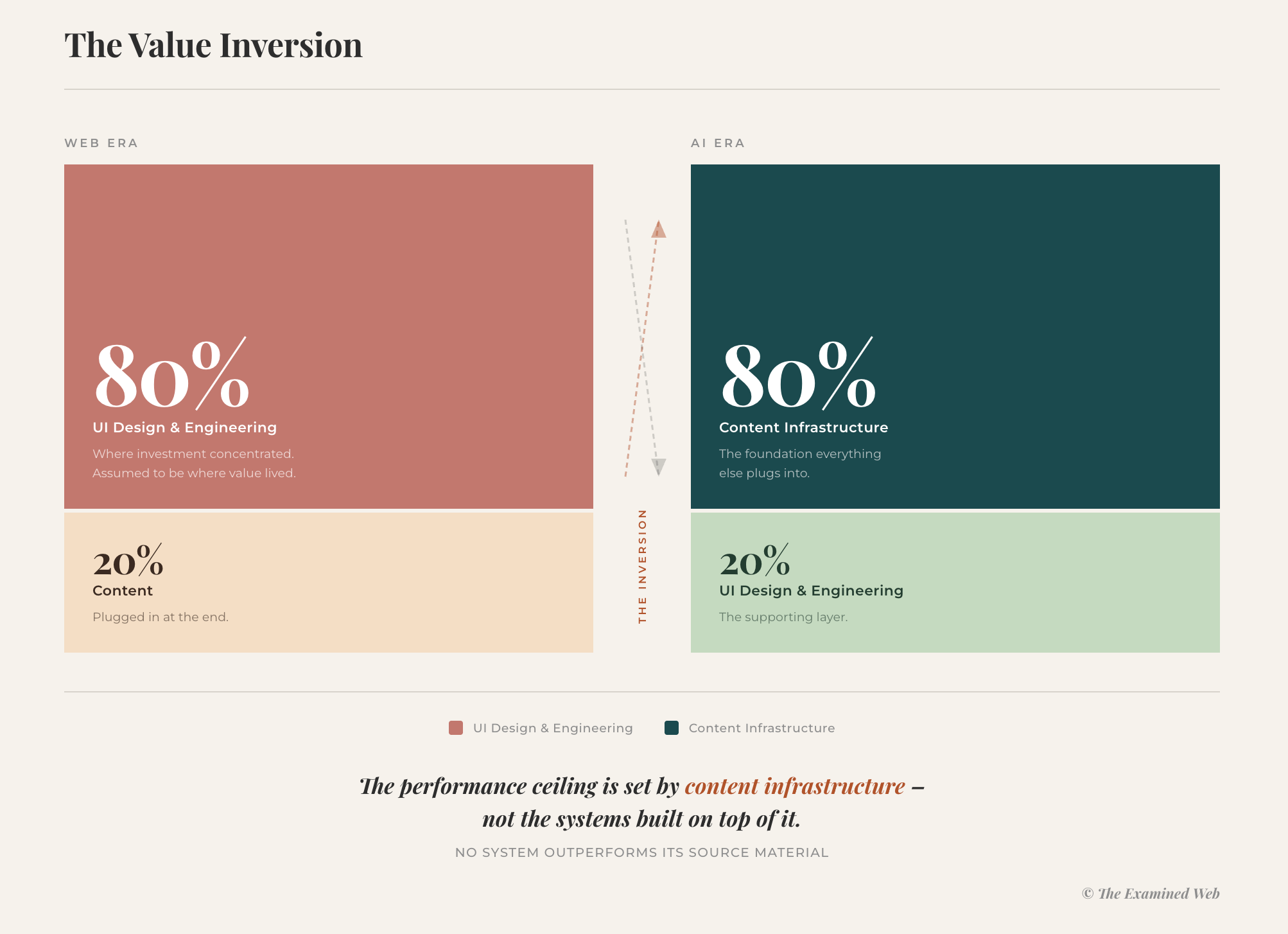
AI inverted this.
The flip
With AI, the interface is commodity. Every chatbot looks roughly the same. Every search box works similarly. The visible layer – what organisations obsess over in demos – is perhaps 20% of the value.
The other 80%? The content infrastructure underneath.
‘Content infrastructure’ isn’t a term that arrived with the AI hype cycle. It describes a specific, multi-layered system of capabilities.
Substance – the editorial quality layer
Where maturity starts.
Do you have a consistent, coherent, relevant body of content to feed an AI system?
Is the writing clear enough for AI to synthesise?
Does terminology stay consistent across departments?
Do marketing promises align with what support documentation actually says?
Without substance-layer maturity, nothing else works. You can’t structure what isn’t coherent. You can’t govern what nobody has made consistent. Most organisations stall here – they’ve never invested in making their content accurate, consistent, and current across the enterprise.
Bottom line: quality gaps at this layer set an absolute ceiling. No amount of technical tuning compensates for contradictory or outdated source material.
Structure – the semantic architecture layer
Once content is coherent, it needs to be organised for AI retrieval and understanding.
Is there a unified taxonomy and metdata schema, or do five departments use five different names for the same product?
Is content semantically mapped and modelled so AI can understand relationships between concepts?
This is where content architecture and knowledge engineering live. But this work presupposes that the substance layer is already sound.
Architecture organises meaning. It does not create it.
Bottom line: structural fragmentation means AI retrieves the wrong content – or nothing at all.
Governance – the content operations layer
Content needs governance to stay coherent over time. Who owns accuracy? What happens when products change – does documentation update, or does outdated content accumulate alongside current content? Are there workflows ensuring quality control?
Knowledge AI governance operates on two surfaces.
Organisational content governance covers the human ownership model: workflows, standards, and policies that define how content gets created, maintained, and kept current.
AI system context governance covers the system’s own operating parameters: role scope, skills, workflows, and guardrails that define how it executes within that organisational context.
Both are content governance problems. Both deteriorate without active ownership.
Bottom line: even when substance and structure are strong, governance gaps mean quality decreases. Performance isn’t just about current state – it’s about sustaining that state over time. Most organisations are managing neither surface.
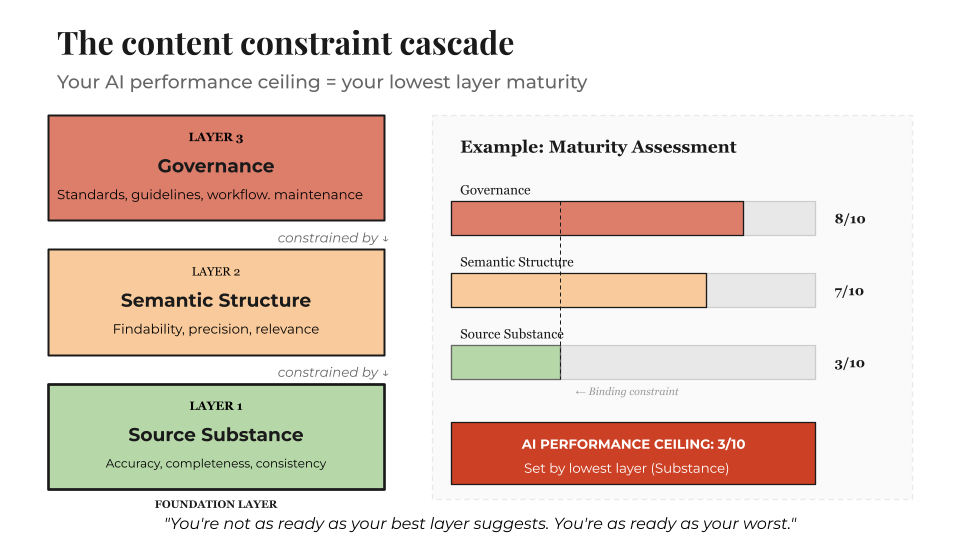
The maturity sequence
Rather than being independent, these layers represent a sequential progression:
Substance first: Get content consistent, accurate, and current
Structure second: Architect content for AI retrieval and semantic understanding
Governance third: Establish the operations that keep it coherent over time
Most organisations want to jump straight to structure – hiring content architects and knowledge engineers to build taxonomies and ontologies.
But you cannot semantically engineer meaning out of incoherent source material. The sequence exists because each layer sets a limit on what the next can achieve.
A content infrastructure assessment reveals not just what’s broken, but which layer the problem originates in – and what sequence of work will actually address it.
The questions to ask:
What does the AI learn from?
How accurate and consistent is that knowledge?
Who governs what’s authoritative?
How do contradictions get resolved?
These questions didn’t matter much in the web era. A human could paper over inconsistencies. A support agent could interpret confusing documentation. A sales rep could translate between Marketing-speak and Engineering-speak.
AI can’t. It synthesises exactly what you feed it. Incoherent foundations produce incoherent outputs – at scale, instantly, to every user.
This is the inversion: content went from ‘the thing you plug in at the end’ to the infrastructure everything else plugs into.
Most organisations are still operating as if the old model applies. Still evaluating AI by interface quality. Still assuming content will sort itself out. Still treating the 80% as an afterthought.
Content debt: Twenty years of shortcuts
The inversion wouldn’t be so consequential if organisations had solid content foundations. Most don’t.
For two decades, content strategy was systematically squeezed out of digital investments. ‘Hire designers and engineers – content will happen.’
Every year, a little more fragmentation. A little more inconsistency. A little more debt accumulating.
Content debt – the accumulated cost of shortcuts, fragmentation, and underinvestment in content operations – compounds like financial debt. And like financial debt, you can ignore it for a surprisingly long time. Until you can’t.
Consider a mid-sized B2B software company evaluating AI-enhanced enterprise search. The interface demos cleanly. Results look instant. AI-powered ranking seems intelligent. The vendor promise is the same whether they’re buying an off-the-shelf product or building their own agentic search capability: make all your content findable, in days.
They commit £120,000.
Three months later, the project sits unused. Search results are incoherent. Employees still message colleagues on Slack to find anything. The implementation is quietly shelved.
Nothing was wrong with the technology. Nothing was wrong with the implementation team. The constraint applied regardless of the approach they chose – bought or built.
The problem: twenty years of content debt, now exposed.
The same product described five different names across departments
Contradictory information and messaging between departments
No governance over what’s authoritative
Metadata so inconsistent the AI couldn’t map relationships
The tool worked. It faithfully surfaced exactly what it found: chaos.
Content debt has been able to accumulate subtly. Marketing and product use slightly different terminology – nobody notices because the website still works.
Engineering documents in one system, support in another, sales in a third – nobody notices because each team finds their own materials.
A merger happens, two taxonomies collide, nobody reconciles them because there’s no budget. Years later: seven different definitions of ‘onboarding,’ three competing product terminologies, orphaned content everywhere.
Nobody paid attention because websites still worked. Suboptimal – users complained that content was hard to find, terminology was confusing, information contradictory. But functional.
The human buffer compensated. Users browsed broken navigation, reconciled contradictory information, called support when content fell short. That labour masked the constraint for decades.
AI removed the buffer. The debt has always been there. It’s the consequences that have changed.
The web-era cost of content debt was: suboptimal websites, confused customers, frustrated employees. Annoying, but manageable.
The AI-era cost of content debt is: failed six-figure implementations, missed opportunities, competitors who addressed their content foundations pulling ahead.
AI systems don’t just display content the way websites do. They ingest it, index it, retrieve it, synthesise it, generate responses from it.
When that content is fragmented, inconsistent, and ungoverned, AI has nothing coherent to work with. The technology works fine. The foundations don’t.
Twenty years of content debt. Now the bill is due.
The urgency trap
Every organisation is facing AI pressure. Boards asking ‘what’s our AI strategy?’ Competitors announcing initiatives. Vendors promising transformation in weeks.
That pressure creates urgency. And urgency is where the content debt trap deepens.
Organisations feel they must act on AI now – but without understanding what those investments actually demand of their content infrastructure, urgency compounds the problem rather than solving it. Interface quality doesn’t predict operational value.
Technical sophistication doesn’t compensate for substance-layer gaps. And implementations on unassessed foundations tend to surface the debt rather than sidestep it.
What organisations can do is get clear on what their AI investments will require before the contract is signed.
The organisations succeeding with AI are focused on sequencing correctly, rather than speed. Which starts with addressing the foundations of what AI readiness for language-based systems means.
Content isn’t the 5% you plug in at the end. It’s the 80% that everything else plugs into.
Coming up
This is the first of a series laying out a complete framework for understanding AI’s content-shaped performance constraints.
Coming in the series: why content infrastructure is being conflated with content architecture across AI strategy discourse, why the engineering community has spent 18 months iterating on problem definition rather than implementation, the backwards implementation pattern, two blindnesses and two wrong turns, the 29 knowledge AI opportunities most organisations don’t know exist, and the assessment methodology and investment sequence that works.
By the end, you’ll have a complete picture: why implementations fail, what organisations miss, and what the sequencing looks like when it works.