The substrate paradox
The layer that determines whether your AI works is the one nobody's looking at.


For two decades, organisations have been improving digital systems. Interfaces got better. Platforms got faster. Software became genuinely more usable. From the outside, it looks like steady progress – and in the places you can see, it largely was.
Underneath, very little changed.
The way organisations produce, structure, and maintain what they know – their documentation, their product information, their policies, their institutional expertise – remained fragmented, inconsistent, and largely ungoverned.
We got dramatically better at presenting information. We did not build better systems to produce it in a way that creates shared meaning.
Content debt: Twenty years of shortcuts, past due
The result of two decades of ignoring the substrate has a name: content debt. The accumulated shortcuts, the fragmentation, the governance challenge that got kicked down the road for another time.
For a long time, that didn’t matter. Because there was a buffer: humans.
When a website was unclear, users (the technical jargon invented for when a human being has a screen in front of their face) navigated around it. When information conflicted, they reconciled it themselves. When content failed, they called support.
The system didn’t need to be completely coherent. It just needed to be good enough for a human to compensate for it being barely coherent.
That buffer is gone.
AI systems don’t navigate around ambiguity – they expose it. They cannot distinguish reliably between conflicting versions unless the source material carries governance signals that make those distinctions legible. They don’t compensate for weak source material. They operate on it, at scale, with outputs that appear confident regardless of whether they’re correct.
Which means something that was always true, but rarely consequential enough to fix, has become unavoidable: every digital system runs on a substrate, and in knowledge systems, that substrate is content.
This is where most organisations misdiagnose what’s happening. They’re treating language-based AI the same way they treated data systems – as an engineering problem. That works when the system processes numbers. It breaks when the system processes meaning.
Quantitative systems depend on data infrastructure: pipelines, warehouses, schemas. Improve those and performance improves.
Knowledge systems depend on something else entirely – the quality of the source material, how it’s organised, how it’s maintained over time. Structure doesn’t fix unclear thinking. Pipelines don’t fix inconsistency. Engineering cannot compensate for a lack of meaning.
Content has never been more important to business transformation – at precisely the moment it has become least visible to it.

The structural squeeze
Attention on AI initiatives gets pulled in two directions simultaneously: upward toward what’s visible (interfaces, demos, customer-facing features) and downward toward what can be built (models, platforms, custom infrastructure).
Between those two forces, the layer that actually determines whether any of it works gets missed entirely.
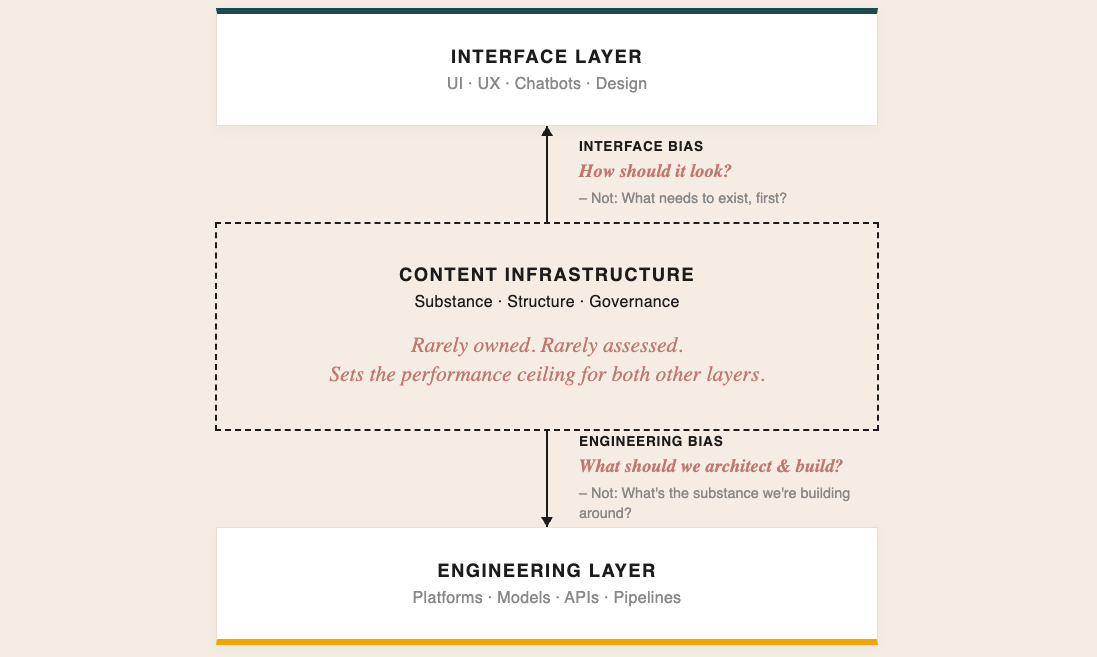
That is the paradox. The layer that determines whether the system works is the one layer neither interface bias nor engineering bias has any reason to look at.
Organisation deploys an AI tool. Performs well in controlled conditions. Underperforms in production. Performance plateaus at 30, 40, 50 percent of what was projected.
There is now an accumulated body of research reporting on the high failure rates of AI implementation in enterprise. If you want the evidence in your hands: Google it. Or ask AI.
The shape of the failure is increasingly familiar.
Product names conflict across teams. Guidance exists in multiple versions. Ownership of accuracy is unclear. The system hasn’t failed. You might even say that it’s actually done a bloody good job of surfacing the state of the organisation’s knowledge.
The buyer assumed it was purchasing a magic black box. It had unknowingly bought a floor-to-ceiling mirror.
The response – optimise the model, refine the prompts, increase the budget – doesn’t materially shift the outcome. The constraint was set before the system was deployed. It was set by the content infrastructure feeding it.
An LLM is optimised to sound confident and authoritative. Being correct is not what it’s actually doing.
The last thing you’ll ever get back from any AI model is this:
“I’m sorry, what you’re telling me doesn’t make much sense. I can’t work under these conditions.”
Give an LLM almost any prompt, no matter how incoherent, and its default behaviour is to work with it – to normalise it, extend it, and make it sound plausible. Stopping the exchange to say "this doesn't make sense" is not what these systems are built to do.
The same logic is why website redesigns so often produce a temporary lift rather than a lasting change.
You can redesign the surface as many times as you like. The ceiling is set underneath it.

Agentic systems remove the last checkpoint
Agentic systems make this significantly harder to ignore. A retrieval system that surfaces wrong information is an annoyance.
An agentic system that acts on it – planning, retrieving, analysing, executing, without a human checkpoint in between – is a different kind of problem.
Every inconsistency, every gap, every ambiguity compounds through the chain. In customer support workflows, that can mean a system confidently resolving a query against outdated policy logic, obsolete product guidance, or contradictory service rules.
None of this is a technology problem.
In every organisation, a knowledge system already exists – it’s just not designed. Marketing writes one version. Product writes another. Support maintains a third. Ownership is assumed rather than assigned. Standards are implicit rather than documented. Maintenance happens reactively, when something breaks badly enough that someone notices.
Individually, none of that is new. Collectively, it defines the ceiling every system runs into, regardless of how sophisticated the technology sitting on top of it becomes.
The organisations that understand this will approach the next phase differently.
They’ll start with the substrate – clarifying what’s actually known, structuring how it’s organised, defining how it’s maintained – before deploying systems on top of it. They do that because it’s the only way the systems perform.
The question is no longer what your system looks like. It’s what it knows, and whether that knowledge can be trusted.
Before the architecture conversation
That question has a methodology.
A content infrastructure diagnostic runs before the architecture conversation, before the vendor evaluation, before the first procurement decision.
It maps what the organisation actually knows – and what it would need to address before any system built on top of that knowledge could be trusted to perform.
Most organisations reach it in the post-mortem. It works considerably better at the start.
