The context mirage: Why AI has engineering stumped
'Good context' isn’t a precondition you can engineer. It’s a net-outcome of whether your content makes sense.

Technology transitions follow a familiar pattern: chaos, then convergence.
Cloud computing took a decade to stabilise. DevOps sparked years of argument. Microservices still divides opinion at the edges.
But in every case, the disagreement was about implementation. The engineering community converged quickly on what the root problem was – even when how to solve it remained hotly contested.
NIST had a workable definition of cloud computing by 2011. DevOps arguments were fierce, but nobody was confused about the goal. Microservices debates were architectural – not definitional.
Engineering disciplines generate implementation debates that last years. What they don’t do is spend 24 months unable to stabilise the definition of the problem they’re solving.
Now look at AI implementation that runs on language models.
2024: prompt engineering – the problem is how you phrase the question.
2025: context engineering – no, hang on… the problem is how you architect the information environment.
And the sequence continues – in more niche corners, off-shoots of the same debate appear.
‘Intent engineering’ (no, the real skill is articulating the objectives and outcome constraints to your agent), and even ‘specification engineering’ (yes but also… let’s remember about precise specifications).
That’s not an implementation debate. It’s a discipline encountering a problem it doesn’t yet have the vocabulary to resolve.
Each new iteration a fresh attempt to name what the previous one couldn’t: the actual requirement in each case boils down to providing AI systems with coherent, relevant content assets that machines can read.
And the master skill in question is more editorial than architectural.
The category error hiding in plain sight
When disciplines fail to converge on problem definition, it usually means the problem sits outside the domain attempting to define it.
The divergence here – at the level of what the problem is – points toward a boundary condition: tools developed for one class of problems being applied to a fundamentally different class.
The current dominant term gives the game away.
Because context engineering contains a category error in its own name. Engineering implies construction – specify requirements, build components, assemble a system.
But ‘good context’ isn’t something you build. Context is what good content infrastructure produces.
You cannot engineer the output while skipping the process that generates it.
This is not an argument against context engineering. The technical discipline is real. The optimisation is legitimate.
But it operates downstream of something it cannot itself produce – and that upstream dependency is where most AI implementations hit their ceiling.
The name encodes the mistake. 18 months of core definitional language iteration, with no sign of convergence, encodes the proof.
The course correction that still can’t hold
Prompt engineering arrived first, and with confidence. Better inputs, better outputs. Courses launched overnight. Job titles appeared. The implicit assumption: the problem is how you phrase the question.
It didn’t hold. It couldn’t. Output quality turned out to depend far more on what the system could access than on how you asked.
Context engineering was the legitimate correction. The problem isn’t the question – it’s the information environment the system operates in. Retrieval architecture. Memory management. Knowledge graphs. The implicit assumption revised: fetch the model the right information, and it will produce the right output.
This is closer. It’s also the point where the unexamined premise becomes visible.
Context engineering presupposes that the information being retrieved is coherent, consistently structured, and organised in ways the system can navigate. When the underlying content contradicts itself across systems, sophisticated retrieval doesn’t solve the problem. It retrieves the contradiction efficiently.
The correction was real. The upstream assumption was still unexamined.
The engineering community hasn’t been secretly ‘doing content strategy’.
It’s been building technically legitimate systems that keep encountering the same upstream constraint – and reaching for new vocabulary each time it does.
That’s not a failure of engineering. It’s a boundary condition.
To understand the challenge of context engineering, let’s look at Pokémon.
Said no one, ever.
Oh hang on, except (checks notes)… Anthropic.
Anthropic’s guidance on context engineering is rigorous and precise. It defines the task of context engineering for AI agents as:
“Find the smallest possible set of high-signal tokens that maximise the likelihood of some desired outcome.”
That is a valid optimisation problem. Context windows are finite. Attention budgets degrade with scale. Token management matters.
But the formulation contains an unexamined premise.
High-signal… relative to what?
Signal doesn’t exist independently. It depends on coherence, consistency, and accuracy in the source material.
The guidance treats context as something to compress and route efficiently inside a model’s attention window. It does not address how that context is produced – or degraded – upstream.
The most revealing illustration appears in the article’s long-horizon task example: Claude playing Pokémon. The agent maintains detailed tallies across thousands of steps. Tracks objectives. Builds maps. After context resets, reads its notes and resumes multi-hour strategies without losing coherence.
Impressive. Except Pokémon is a completely closed system.
Every rule is defined. Every entity is specified. Terminology is perfectly consistent across the entire environment. The content infrastructure of a video game is structurally flawless.
Enterprise environments are not Pokémon.
Multiple departments. Conflicting terminology. Fragmented systems. Unclear ownership of accuracy. Policies that contradict each other.
Applying techniques proven in a perfectly specified environment to a structurally incoherent one – and expecting similar coherence – is not an engineering failure.
It is a domain mismatch.
The enterprise challenge isn’t just scale
The current engineering discourse handles the challenge of applying the principles of context engineering to enterprise scale with a kind of confident equivalence.
Solo practitioners: just get your file repos and docs into shape.
Enterprises: same challenge basically, just at a larger scale.
As if scale were the only difference. But the logical gap between them is the entire problem.
Taking a fragmented, multi-departmental, politically contested, terminologically inconsistent corpus of organisational knowledge accumulated over decades across incompatible systems – and making it coherent, consistent, and machine-readable – isn’t a ‘context engineering challenge’.
It’s a content infrastructure crisis.
The problem isn’t how you spec in work and ‘context assets’ to the agent. The problem is that the underlying content that defines context is usually not fit to be worked on by any agent.
The specification vocabulary describes what needs to happen. It has nothing to say about how.
You cannot specification-engineer your way out of thirty departments using different terminology for the same product.
You cannot intent-engineer around a substantial knowledge base when nobody owns organisational truth.
You cannot context-engineer coherent retrieval from content that contradicts itself across systems.
Why the loop keeps running
The problem iteration sequence has a structural explanation.
Engineering Bias is the first driver. When AI implementation fails, organisations reach for engineering solutions. Engineering has solved most technology adoption problems of the last three decades.
But knowledge-based AI failures aren’t technology problems. They’re editorial problems wearing technology symptoms.
The instinct to fix them technically is well-funded but consistently insufficient. The engineering quality is fantastic. It’s just applied to a problem that sits upstream of where engineering begins.
Interface Bias compounds it. Decision-makers evaluate AI by what’s visible: chatbot demos, generative interfaces, customer-facing features.
The operational applications where the majority of value lives have no demo, no vendor pitch, no competitive urgency. Investment follows visibility. Visibility is not the same as value.
Together, they guarantee that content infrastructure rarely gets assessed. Almost never prioritised.
Engineering Bias ensures the solution always stays technical.
Interface Bias ensures the problem being solved is always a visible one.
Neither registers content infrastructure as an urgent priority – so it never makes the agenda.
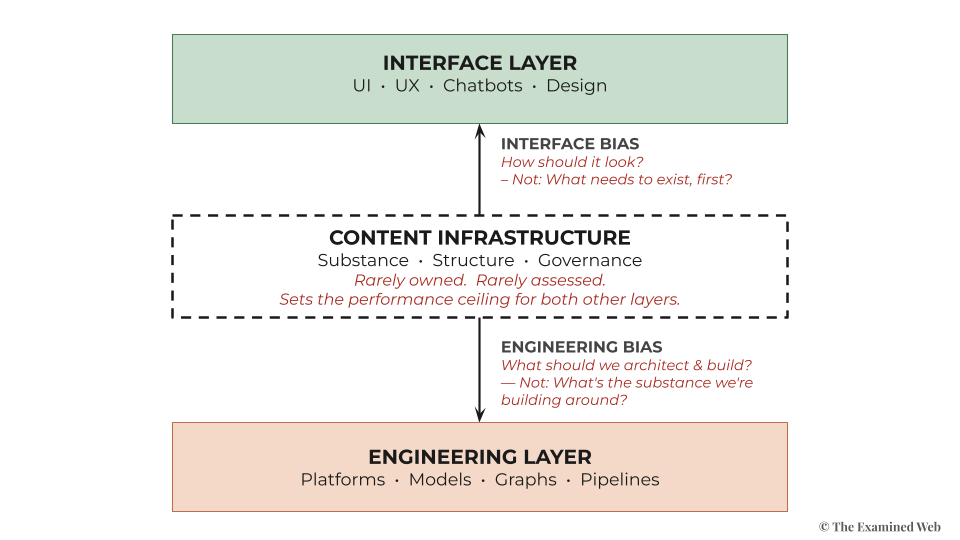
The problem definition iteration loop is what this compound blind spot looks like from inside a single discipline: making genuine progress, encountering the same upstream ceiling, reaching for another technical layer.
Coining another term when the reaching doesn’t land on anything solid.
The Anthropic guidance is what it looks like from the top of the stack: technically rigorous, beginning at the exact point where content infrastructure has been assumed into existence.
This is the mechanical explanation for why the majority of AI implementations stall.
Not inadequate engineering. Systemic oversight built on decades of institutional bias that favours engineering and visual design inputs over editorial judgement – even when mounting evidence shows that editorial judgement is the exact ‘hard skill’ unlock this moment requires.
Organisations investing in the engineering stack while the editorial foundation remains unassessed. Each correction technically sound. Each one discovering, eventually, that the prerequisite input expertise remained out of the picture, just as it was desperately needed the most.
The missing layer
The proliferating terms are the signal: the problem sits one layer above the domain attempting to solve it.
Engineering isn't the right domain for solving content problems. Content is.
Each iteration of the problem definition names a real prerequisite. But the pain lies in discovering each one after the expensive AI investment has been made, rather than before it.
Before deep-diving into context engineering or following the latest guidance on token efficiency – ask a more fundamental question: what can your content infrastructure actually deliver today, and what gap exists between that and your intended AI outcomes?
That’s a content infrastructure strategy question. The engineering community is multiple iterations into discovering the same thing, even if wrapped in language that makes it ‘sound engineering’.
Engineering isn’t failing to solve AI implementation.
It’s just discovering – one layer at a time – that the problem begins before engineering does.