AI readiness demands something engineering can’t provide
Language-based AI demands something outside the reach of traditional engineering expertise. Quality, governed, coherent content as its input.

The big-picture enterprise thinking that defined the first wave of content strategy practice in the 2000s – cross-departmental coordination, editorial governance at scale, information architecture as business infrastructure – gave way to something narrower. Product-centric content design took the foreground. Marketing claimed the rest. The market rewarded tactical focus, and the discipline adapted.
But something has been shifting. As understanding deepens about what knowledge AI systems actually require – context, strong organising schema, scaled governance of information quality – something the industry has been circling for two years is now unavoidable.
Knowledge AI has exposed something the industry overlooked for twenty years: enterprise content strategy was never optional infrastructure. It was deferred infrastructure.
Knowledge AI needs enterprise content strategy. Not the narrowed, interface-focused content design version or the ‘content strategy = marketing content strategy’ versions that came to dominate current practice.
I mean: the full-scope, cross-departmental, infrastructure-grade version of enterprise content strategy that the discipline was originally built to deliver.
This piece traces how we got here – through the prompt engineering moment, the context engineering correction, and into the territory that neither conversation has properly addressed yet.
The prompt engineering moment
If you had even a passing interest in AI business trends through 2024 and into 2025, you encountered prompt engineering. It was everywhere. LinkedIn courses, enterprise workshops, job titles.
The framing was seductive and intelligent: AI gives better outputs when you give it better inputs.
Prompt engineering was advice about how individuals should talk to chatbot interfaces for better results. And for individual use, it works. Anyone who has compared a vague prompt with a structured one knows the difference is real.
But the moment AI moves beyond individual productivity, the limitation appears: the system can only operate within the context it’s been provided.
If you wanted to start using AI to assist with actual project or organisational-scale operations, then it doesn’t matter how well individual employees can phrase a query. The system needs access to quality, well-structured, and maintained information as its starting point for any incoming prompts.
Enter context engineering.
The context engineering correction
By late 2025, the conversation had evolved. Context engineering emerged as the more robust answer to the question of how to feed an AI with the right set of background information it requires to perform the more sophisticated role it was being primed to perform.
This is the threshold moment where AI output quality switched from being a matter of individual tactics to a matter of infrastructure preparation.
Prompt engineering focused on the question, context engineering focused on the infrastructure that feeds AI the right information, at the right time (right information, at the right time... content professionals in the room: starting to sound familiar?).
This was a meaningful advance. Engineers correctly identified that the quality of an AI system’s outputs is determined far more by what it can access than by how you phrase the request. A perfectly prompted query against a poorly organised knowledge base still returns poor results. A mediocre query against well-structured, well-curated information returns something useful.
What the engineering conversation often leaves implicit is this: context isn’t something that just exists.
Context is in itself an outcome effect of providing the right information, at the right time, to achieve a stated goal or output. What is it, the source material, that’s defining that context at an infrastructure level? Content.
Context is downstream of content. The substance, structure, and governance of organisational content is what determines context quality at scale.
But before getting to that, it’s worth noting a historical parallel. Because this isn’t the first time an industry has discovered that content needs infrastructure-grade treatment.
A familiar pattern
If you were working in digital in the early 2000s, you watched something remarkably similar play out.
The first generation of web projects was technology-led. Build the CMS. Design the interface. Launch the site. Content was assumed to be available – something that would fill the containers once the real work of engineering and design was complete.
It wasn’t available. Or rather, it was available in the way that most enterprise content is available: scattered across departments, inconsistent in quality, contradictory in terminology, owned by nobody in particular. The sites launched. The content was a mess.
The last time the industry made this mistake, a discipline emerged to correct it.
Ann Rockley’s Managing Enterprise Content in 2002 and Kristina Halvorson’s Content Strategy for the Web in 2008 articulated the same core insight:
Content is not a commodity that fills containers. It’s a strategic asset requiring coordination, editorial standards, structural planning, and governance across organisational boundaries.
That insight was revolutionary. It was, in hindsight, also ahead of its market. Through the 2010s, the economics of digital product development favoured tactical focus.
Content design instead emerged as a more immediately actionable practice – crafting interface language, standardising product content patterns, streamlining task flows, aligning content with user journeys. This was the flavour of content work that the market favoured and rewarded.
Content strategy practitioners adapted accordingly. The enterprise-level lens – the cross-departmental editorial strategy, information architecture work, and content governance frameworks – gradually lost their organisational home.
Nothing to do with professional failure. Everything to do with rational market signals.
In the web application era, the cost of ungoverned enterprise content was high but largely tolerable. Users compensated for content gaps through their own effort – browsing, comparing, exercising judgement. The business case for enterprise-wide content coordination was theoretically sound – but practically difficult to quantify against the immediate, visible returns of optimising the performance of product user journeys.
The discipline contracted. The problems it was built to address didn’t go away. They accumulated.
And now – as with the early web – a new technology is exposing exactly what was left unaddressed.
What individual AI users are already discovering
Back to context engineering – and what’s happening as it matures beyond the engineering community.
Individual users are figuring something out. Not in theory, but through daily practice.
Anyone who has spent serious time using AI as a working tool – a research assistant, a writing partner, a thinking aid – has gone through a version of the same learning curve. Early on, you focus on prompts. How do I phrase this to get a better answer? That’s the prompt engineering phase. And it works, up to a point.
Because what happens next is that you start realising the bottleneck isn’t how you ask. It’s what the system has been given to work with before you ask a thing.
So you begin curating those materials. The context. You feed it past report examples so it understands the format you need. You provide writing guidelines so outputs match your voice. You upload organisational context – your personal website, blog articles, planning documents, branding, product specs – so the system has the reference material it needs to produce something genuinely useful rather than generically plausible.
In other words: you build a personal content infrastructure. A curated, organised, governed set of reference materials for your AI system to draw from and cohere against.
This skillset and effort may have quickly come to be known as context engineering – but anyone with any sort of background in content strategy knows: this is doing content strategy for a team of one.
Selecting what materials matter in support of stated goals (and vice versa), structuring it for the highest-signal consumption, and maintaining it as things change and feedback loops point to incremental improvement.
The content dependency is the lesson everyone learns: the quality of AI output is constrained by the quality, completeness, and coherence of the content you feed it. Not by the model. Not by the prompt. By the substrate.
Now let’s scale that realisation.
An individual curating context for their personal AI assistant is manageable. One person’s reference materials. One person’s quality standards. One person’s judgement about what’s current and what’s outdated.
An organisation with 2,000 employees across six departments and four geographies faces the same dependency at a completely different order of complexity.
The knowledge that feeds the enterprise AI system needs the same coherence that an individual user painstakingly builds for their personal setup – but across multiple content platforms, departmental boundaries, content ownership silos, inconsistent editorial standards, and two decades of accumulated, ungoverned material.
Gulp.
Nobody is curating the organisational equivalent. Nobody is governing the reference materials that the enterprise retrieval system treats as ground truth. Nobody is ensuring that the product definitions, organisational messaging, and knowledge base materials are consistent, accurate, relevant, and up-to-date across departments and global regions.
The individual user’s learning curve – prompt craft matters less than context quality, and context quality depends on content infrastructure – is a leading indicator of what enterprises are about to confront at scale.
The dependency is identical. The complexity scale difference is monumental.
But there’s a professional practice that is pre-qualified to address content substance, structure, and governance quality at that scale.
It’s just been dormant in the AI space up until now.
Enterprise content strategy.
Content as infrastructure: three layers, three performance ceilings
When you treat content not as a commodity output but as infrastructure that sets performance ceilings for knowledge AI systems, a different assessment framework emerges.
Quantitative AI – the kind that processes numerical data, detects patterns in structured datasets, optimises logistics – requires data infrastructure. Clean, structured, governed data. Most enterprises have invested decades in building this capability. Data engineering is a mature discipline with established practices, tooling, and organisational recognition.
Enterprises would never run quantitative AI on unclean, ungoverned data. And yet. They routinely deploy knowledge AI against unstructured, unowned, and unmaintained content — and are surprised when performance degrades.
Knowledge AI – the kind that processes qualitative content, retrieves information, synthesises guidance, generates responses grounded in organisational knowledge – requires content infrastructure. And most enterprises have built almost none of it.

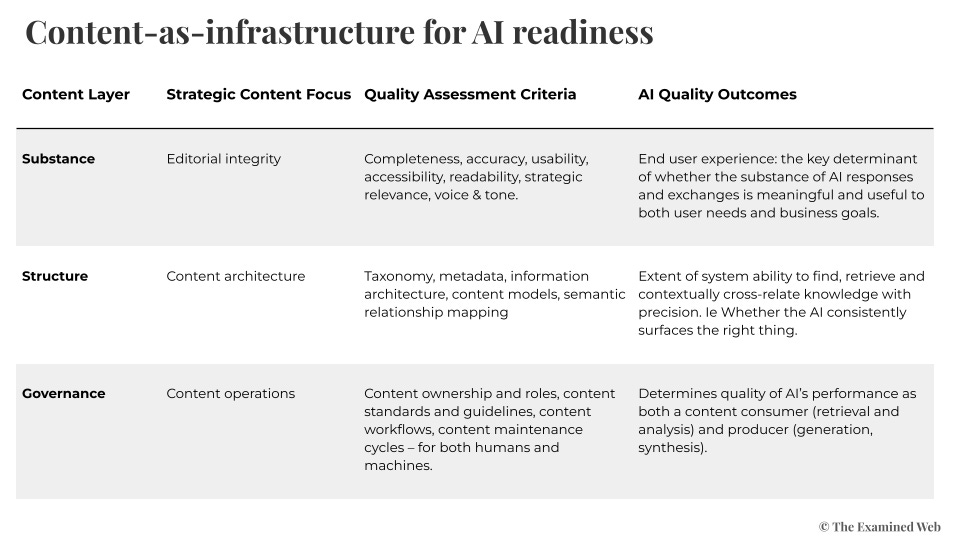
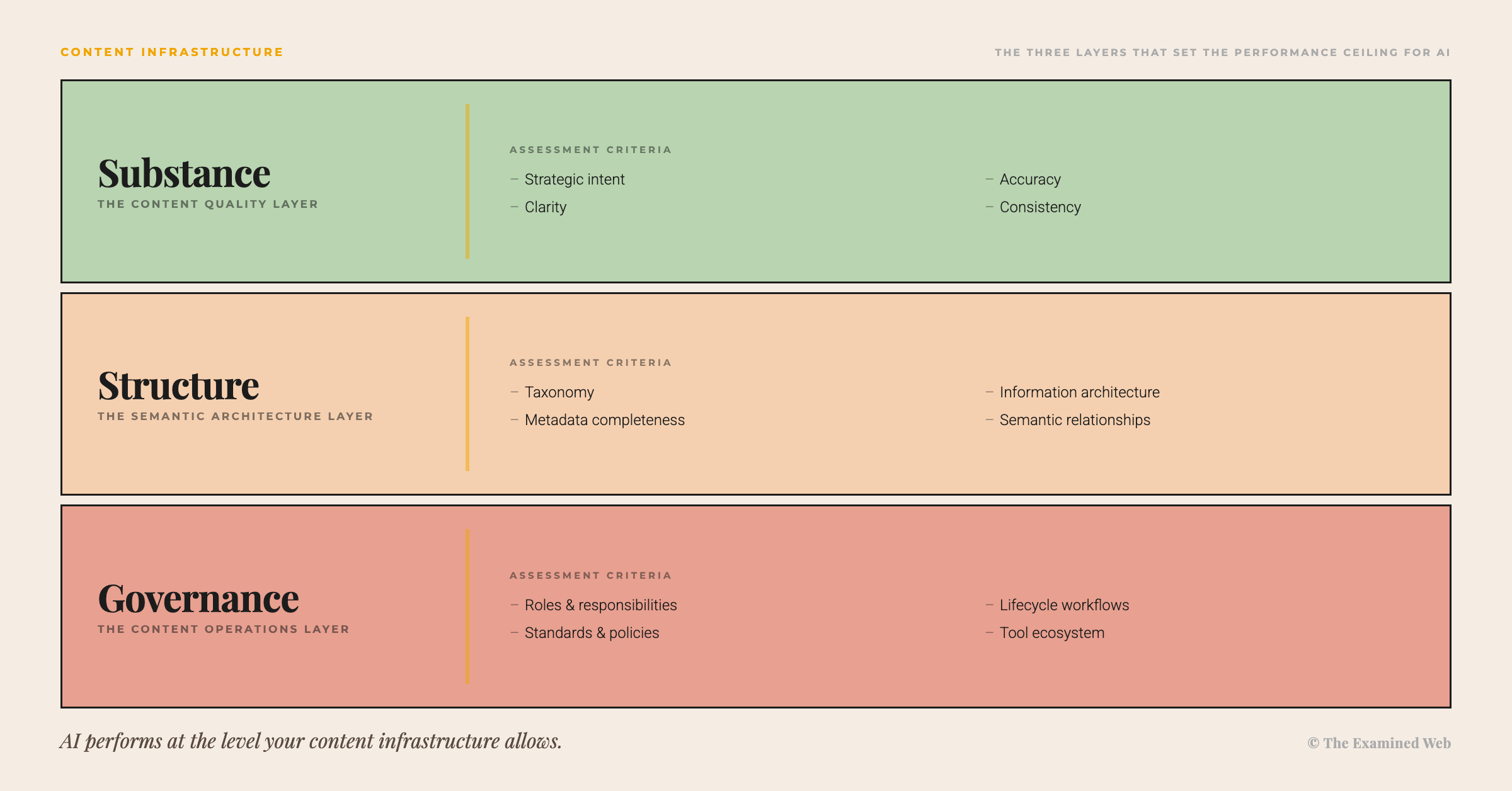
Content infrastructure has three layers. Each sets a ceiling that determines what AI can achieve – and each constrains the layers above it.
Substance is the editorial foundation. Completeness, accuracy, readability, accessibility, strategic relevance, voice and tone consistency. This layer determines whether AI responses are meaningful, accurate, and useful. It’s the equivalent of data quality in quantitative AI – and it’s the layer most organisations assess least. An AI system grounded in incomplete, outdated, or contradictory content will produce incomplete, outdated, or contradictory outputs. No amount of architectural sophistication changes this.
Structure is the organising schema. Taxonomy, metadata, information architecture, content models, semantic relationship mapping. This layer determines whether retrieval is precise – whether the system consistently surfaces the right information in the right context rather than returning everything vaguely related. Structure is where context engineering and content infrastructure overlap, and where engineers most often discover gaps they didn’t anticipate. Without coherent structure, retrieval degrades from “find the answer” to “find twenty things that might contain the answer.”
Governance is the operational framework. Content ownership, standards and guidelines, workflows, maintenance cycles, cross-departmental coordination. This layer determines whether performance is sustained as the system scales and content evolves. It’s the most chronically neglected layer because it’s the least visible. Governance failures don’t produce dramatic crashes – they produce slow degradation. The AI that worked brilliantly in the pilot gradually becomes less reliable as ungoverned content drifts from accuracy.
The dependency logic matters: each layer constrains the one above it. You cannot meaningfully structure incoherent content – taxonomy applied to inconsistent terminology just organises the mess more neatly. You cannot govern what nobody owns – workflows for content maintenance require someone to maintain. And you cannot engineer around a lack of substance – retrieval architecture that efficiently surfaces poor-quality content just delivers poor quality faster.
Where this leads
Three implications follow from this.
First: any enterprise assessing “AI readiness” without assessing content infrastructure is likely running a glaringly incomplete diagnostic. Context engineering without content infrastructure is building a delivery system for cargo that hasn’t been loaded.
The most sophisticated retrieval architecture in the world cannot compensate for source material that’s incoherent, contradictory, or unmaintained. Readiness assessments that evaluate only technical architecture and data pipelines are answering half the question.
Second: the widely reported high failure rates of enterprise AI initiatives aren’t primarily a technology problem. The technology works. Context engineering works. What fails is the assumption – almost never examined – that organisational content is ready to be processed at scale. It rarely is.
Twenty years accumulation of content debt across platforms, departments, and business units, without the infrastructure-grade governance that’s applied to data, has produced exactly the foundation you’d expect.
Fragmented, inconsistent, ungoverned, and invisible to the teams making six-figure procurement decisions.
Third: the expertise required to assess and remediate content infrastructure exists and is available. It emerged from a discipline that contracted its scope during an era when the market didn’t reward the work. The market now demands it.
The question facing enterprises isn’t whether content infrastructure matters for knowledge AI – it does, structurally and unavoidably – but whether they recognise the gap before or after the next implementation underperforms.
The trajectory from prompt engineering through context engineering pointed in this direction all along. Each step got closer to the actual constraint.
The final step – acknowledging that content itself is infrastructure, with its own assessment requirements and its own performance ceilings – is the one the industry has yet to take.
It will. The industry will get there.
The only variable is how much underperformance happens first.